Research Decoded
Join the EulerFold community
Track progress and collaborate on roadmaps with students worldwide.
LLaVA: Visual Instruction Tuning
Liu, H., Li, C., Wu, Q., & Lee, Y. J. (2023). Visual Instruction Tuning. arXiv:2304.08485.
Read Original Paper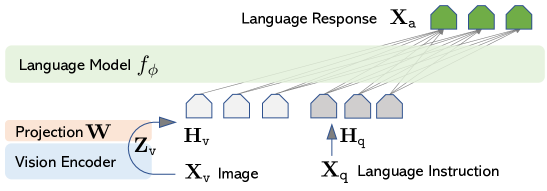
The emergence of LLaVA in 2023 demonstrated that the most effective way to teach a machine to see is not through more complex vision models, but through better language instruction. Before LLaVA, multimodal models were primarily trained for narrow tasks like captioning or classification, leaving them unable to engage in open-ended conversation. Researchers proposed a shift: using a large language model to generate synthetic visual instruction data. By flattening an image into a long string of 'visual words,' they showed that a simple linear bridge is sufficient to align vision and language. This revealed that reasoning is a general capability that can be extended across modalities through the right kind of data, suggesting that a model's 'intelligence' is more about how it is taught than how it is built.
The Synthetic Data Proxy

Using GPT-4 to generate instruction-following data from symbolic image descriptions.
LLaVA established a framework for general-purpose visual assistants by combining a simple linear projection bridge with a high-quality synthetic instruction-tuning dataset. By using a large language model as a teacher—instructing it to generate complex visual dialogues based on raw image metadata like captions and bounding boxes—the researchers created a massive set of instruction-following samples that link visual concepts to logical reasoning. The resulting architecture connects a frozen CLIP vision encoder to a language model through a single "translator" layer, allowing the system to "see" visual features as tokens within its existing word embedding space. This shift from simple image captioning toward multi-turn visual reasoning proved that the intelligence of a multimodal system is a function of how its visual senses are aligned with the logical structures of its linguistic brain.
The Minimalist Architecture
The LLaVA architecture showing the linear projection layer bridging the vision encoder and language model.
LLaVA’s architecture is characterized by its simplicity, connecting a pre-trained vision encoder to a language model using a single 'translator' layer. This linear projection layer converts the visual features from the encoder into tokens that the language model can read as if they were normal word embeddings. This architectural choice revealed that complex, multi-stage 'bridging' mechanisms are often redundant when the underlying models are sufficiently powerful. By training the system in two stages—first aligning the visual features and then fine-tuning the entire model on instruction data—the researchers created a system that could 'read' an image with the same fluidity that it reads text. It suggested that the most effective way to build intelligent systems is through the seamless integration of specialized modules that already understand the world in their own way.
Reasoning Beyond Description

LLaVA performing complex visual reasoning on atypical images.
How LLaVA differs from previous multimodal models is most evident in its ability to perform complex reasoning about visual scenes. Instead of merely describing what is in an image, LLaVA can explain the humor in a meme or solve science problems using diagrams. In evaluations, LLaVA achieved a new state-of-the-art accuracy by outperforming previous systems that relied on much more complex designs. This finding proved that once a vision encoder is properly aligned with a language model, the system can apply its general reasoning capabilities to any visual input. It reveals that 'seeing' is not just a perceptual task but a cognitive one, where the meaning of an image is derived from the same logical structures that define human language. This raises the question of whether there is any limit to the types of data that can be integrated into a single, unified reasoning engine.
Dive Deeper
Visual Instruction Tuning (arXiv)
arXiv • article
Explore ResourceLLaVA Project Website
LLaVA Team • website
Explore Resource